
原型的五条规则
- 所有的引用数据类型都具有对象的特性,可以自由的扩展属性
- 所有的对象都有 proto 属性, 它的值是一个对象 proto 也叫隐式原型
- 所有的函数都有 prototype 属性, 它的值也是一个对象 prototype 也叫显式原型
- 引用类型中 proto 指向他构造函数的 prototype 也就是对象的隐式原型指向它构造函数的显式原型
- 当我们获取对象身上不存在的属性时,那么他就会去 proto 中获取
引用数据类型 : Object 、Array 、Function 、Date 、RegExp
使用原型有哪些优点/好处?
我们有一个构造函数,使用这个构造函数实例的对象都有一个 jump() 方法
function Person (name,age){
this.name = name
this.age = age
jump(){
console.log('jump')
}
}
const per1 = new Person('小明',12)
const per2 = new Person('小红',13)
per1.jump()
per2.jump()
上面代码中 jump方法 在堆中存储效果是这样的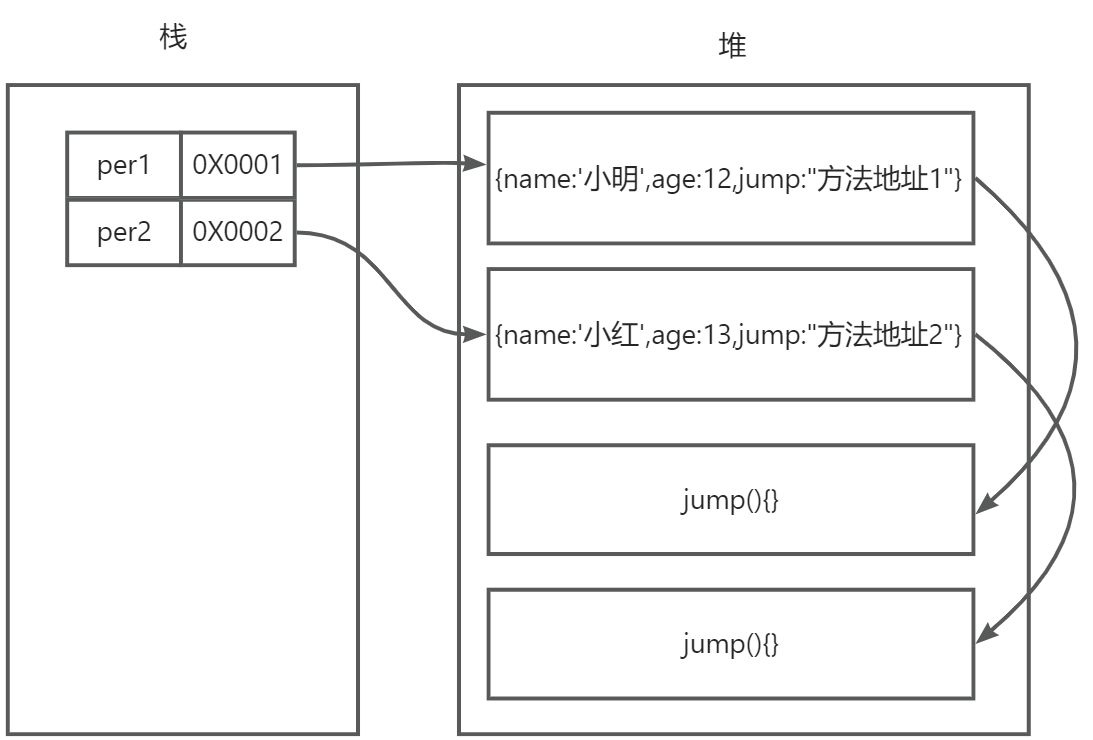
入上图所示会在堆内存中开辟两块空间存放同一个函数
那么我们怎么解决这个问题呢? 原型?
function Person (name,age){
this.name = name
this.age = age
}
const jump = function (){
console.log('jump')
}
// 将jump 方法绑定在 People构造函数的显式原型上
Person.prototype.jump = jump
const per1 = new Person('小明',12)
const per2 = new Person('小红',13)
per1.jump()
per2.jump()
我们将公共的方法绑定在构造函数的prototype上 根据上面的第四条规则
引用类型中 proto 指向他构造函数的 prototype 也就是对象的隐式原型指向它构造函数的显式原型
当我们访问实例对象身上不存在的方法时则会通过 proto 访问到构造函数的 prototype 上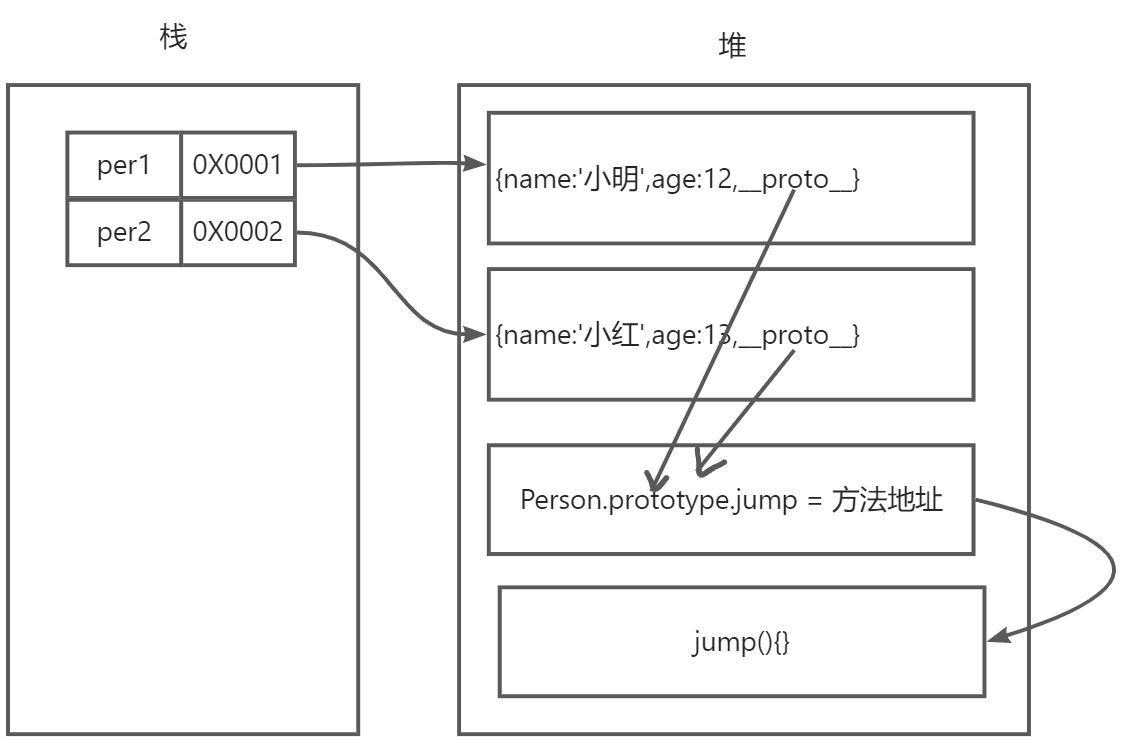
什么又是原型链呢?
看下面这段代码:
function Person(name) {
this.name = name
}
var nick = new Person("nick")
nick.toString
// ƒ toString() { [native code] }
按照道理来说 nick 是 Person构造函数的实例 并且 Person的构造函数上也没有 toString方法 , 那么为什么 nick 可以获取到 toString 方法呢?
这就是原型链 nick 先从自身出发 发现自身并没有 toString 方法 然后 向上找, 找到了构造函数 prototype ,发现也没有该方法 , 然后构造函数 的 prototype 本质也是一个对象 就会接着通过 proto 向上找 找到了 Object.prototype , 所以就找到了 Object.prototype 下的 toString 方法。
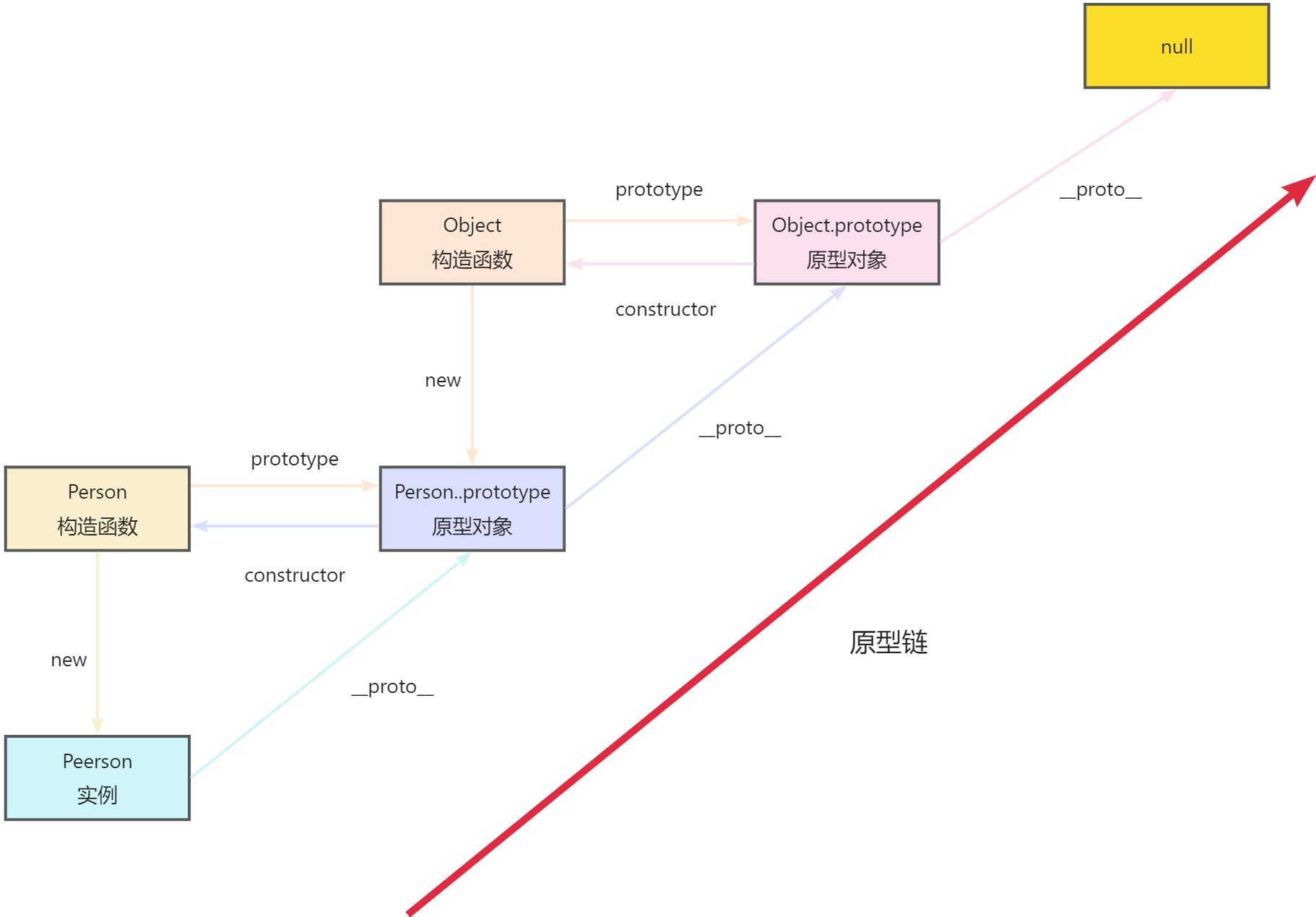
最上级的null 是为了避免死循环 Object.prototype 的隐式原型指向 null。
instanceof 是什么? 是否可以手写实现 instanceof?
instanceof 是检查构造函数的显式原型是否出现在 目标对象的原型链中任意位置
// 检测 R的原型是否出现在L的原型链中
function instance_of(L,R){
//先验证 R 的数据类型
const typeArr = ['number','string','null','undefined','boolean','symbol']
if(typeArr.includes(typeof R)) return
// 获取 R 的显式原型
const RPT = R.prototype
// 获取 L 的隐式原型
const LP = L.__proto__
while(true){
if(RPT === LP){ // 相等返回
return true
}
// 找到了最底层
if(LP === null){
return false
}
// 没有找到则向上一层继续
LP = LP.__proto__
}
}
实现思路 :
如果 构造函数的显式原型 在 对象的原型链中 那么 两者是相等的
如果两者不相等 则向上寻找继续比较 直到null